
For autonomous vehicles (AV) to perform at par with human ability, we first need to understand human driving behaviour. For simplification, human driving tasks can be broken down into two categories of tasks, i.e., the ‘what tasks’ and the ‘how tasks’, together referred to as the orthogonal tasks. The driving task under the ‘what category’ can be further broken down into three hierarchical levels, i.e., navigation, guidance, and stabilisation. Similarly, the driving tasks under the ‘how category’ can be further broken down into three levels, i.e., skill based, rule based, and knowledge based
A very common and popular architecture, which is being extensively used and mentioned in the academia and the industry, is the end-to-end learning architecture for AV. The figure below shows a typical development cycle for an end-to-end learning architecture for AV. In 1989, Pomerleau et al. first showcased the main idea behind this architecture in an Autonomous Land Vehicle in a Neural Network (NN). The idea is to use raw camera images and map pixel values from a NN to produce the final output from the actuators, for example, steering angles. The recent work by a team at NVIDIA, on a similar idea, trained a Convolutional Neural Network (CNN) to produce steering angles using camera images as input.
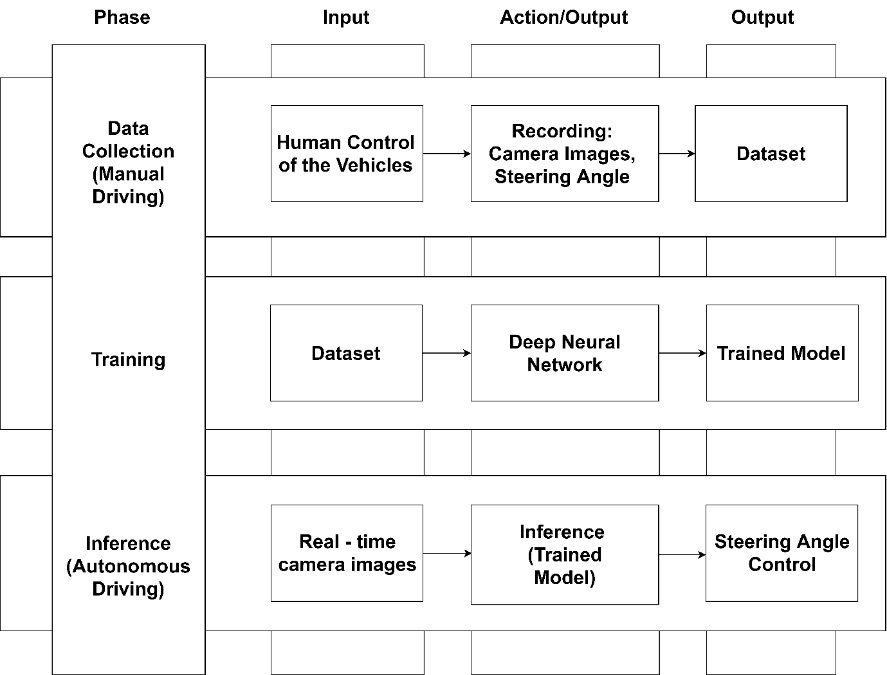
Figure 1. End-to-End Learning architect [1].
In addition to its relatively simple architecture, other benefits of the end-to-end learning architecture are as follows: [1][2][3][4]
- 1. It uses lesser and simpler data. It does not require multiple sets of data coming from different sources as was in the case of the hierarchical software pipeline.
- The CNN is capable of automatically learning the internal representation of important features imbedded with the data. For example, lane marking will be detected automatically if deemed important by the CNN.
- In comparison to the hierarchical software pipeline, the end-to-end learning architecture can simultaneously optimise all the explicit problems such as lane detection, pedestrian detection, path planning, etc.
- It is easier to manage along with being computationally less expensive.
- It is less prone to propagation of uncertainty as there are no intermediate steps which optimise separately.
As mentioned above, the end-to-end learning architecture produces remarkable results, however, in safety, it poses a big challenge because of the following reasons:
- It is difficult to trace the root cause of any failure in a single CNN.
- There is a lack of interpretability in the output/decision because of random initialisation of parameters of NN. Multiple values for parameters capable of producing similar accuracy score leads to trust issues for the end users.
- Using an end-to-end CNN, with no provision for human interference at the intermediate stage, further increases trust deficit.
- Intermediate Fail-Safe mode provisioning becomes difficult in such end-to-end learning architectures.
References
1. A. Platforms, “An End-to-End Deep Neural Network for,” 2019.
2. M. Bojarski et al., “End to End Learning for Self-Driving Cars,” arXiv1604.07316 [cs], pp. 1–9, Apr. 2016, Accessed: Sep. 02, 2019. [Online]. Available: http://arxiv.org/abs/1604.07316.
3. J. Janai, F. Güney, A. Behl, and A. Geiger, “Computer Vision for Autonomous Vehicles: Problems, Datasets and State of the Art,” arXiv1704.05519 [cs], Apr. 2017, Accessed: Sep. 02, 2019. [Online]. Available: http://arxiv.org/abs/1704.05519.
4. L. Tai, P. Yun, Y. Chen, C. Liu, H. Ye, and M. Liu, “Visual-based Autonomous Driving Deployment from a Stochastic and Uncertainty-aware Perspective,” 2019, [Online]. Available: http://arxiv.org/abs/1903.00821.
About the Author: Vibhu Gautam
 Vibhu has studied System on Chip at the University of Southampton, where he graduated with a Master’s degree in 2010. The thesis for this Master’s was in the area of Machine Learning, titled as “A comprehensive approach of peak detection from mass spectrometer data using independent component analysis”. After finishing University, Vibhu worked as a Data Analyst, first for Mckinsey & Company and later for Boston Consulting Group (BCG). Before his current role as a researcher at the University of York, he was working as a Data Scientist at Micron Memory in Japan where he applied Advanced Machine Learning techniques for improving yield efficiency and predictive maintenance. His keen interest in Artificial Intelligence and Machine Learning (AI&ML) drove him back to academia and into this PhD.
Vibhu has studied System on Chip at the University of Southampton, where he graduated with a Master’s degree in 2010. The thesis for this Master’s was in the area of Machine Learning, titled as “A comprehensive approach of peak detection from mass spectrometer data using independent component analysis”. After finishing University, Vibhu worked as a Data Analyst, first for Mckinsey & Company and later for Boston Consulting Group (BCG). Before his current role as a researcher at the University of York, he was working as a Data Scientist at Micron Memory in Japan where he applied Advanced Machine Learning techniques for improving yield efficiency and predictive maintenance. His keen interest in Artificial Intelligence and Machine Learning (AI&ML) drove him back to academia and into this PhD.
![]()