
Safety concern in an autonomous vehicles (AV) primarily arises from the software pipeline which has successfully replaced the human driver, who earlier acted as an integrator and operator of various driving tasks. AV need to perform multiple highly dynamic and complex tasks for which they should be able to generalise any unpredictable situation and this process primarily depends on its software pipeline.
With many prototypes of AV being tested on road[1], the concern for the safety of both human life and the infrastructure has become a pivotal area of research. This safety concern primarily arises from the software pipeline which has successfully replaced the human driver, who earlier acted as an integrator and operator of various driving tasks. AV need to perform multiple highly dynamic and complex tasks for which they should be able to generalise any unpredictable situation and this process primarily depends on its software pipeline.
Although there has been a great amount of improvement in the hardware and sensor technology, the software pipeline remains the biggest barrier in the safety and adoption of AV. Further, the new paradigms like end-to-end learning, as done by Mariusz et al. at Nvidia[2], where a Convolution Neural Network (CNN) is fed with raw camera images to produce steering angle as outputs. This end-to-end learning architecture raises new questions regarding the safety, reliability and human interpretation of the output results which need to be addressed. Another popular approach is a hierarchical software pipeline comprising techniques of localisation, perception, and planning and control, all done separately. The information flow in the software pipeline of an AV consists of the input from raw sensors which is processed for object detection and localisations and then passed down the stream for planning and control. Many of these techniques are based on Machine Learning (ML) and therefore, they are primarily data-dependent.
As ML functions can learn from data rather than being explicitly programmed, they are intrinsically uncertain. Many of the state of art ML techniques can be argued to have non-deterministic learning process, Neural Networks (NN), for example, has a non-deterministic learning process owing to their random initialisation of parameters (weights and biases) and stochastic optimisation technique for loss reduction. Such ML techniques have a very high generalisability; however, this ability makes prediction non-deterministic for inputs belonging to the same set of class. The non-deterministic nature of ML makes their output highly uncertain. From the safety perspective, work done by Lydia et al. [3]argues that these internal uncertainties and non-deterministic nature of ML, as discussed above, lead to a deviation from the intended functionality of ML dependent system and is called functional insufficiencies of such systems. This precisely makes the software pipeline a safety issue.
Due to the increasing dependencies of these tasks on ML, the uncertainty of predictions propagating downstream along with the lack of interpretability of these uncertainties, makes it very challenging for the system to identify and respond to any software failure. Hence, to establish an acceptable level of safety in AV, we need to argue that ML in the software pipeline is acceptably safe.
From the above discussion we have a research hypothesis, which is:
It is possible to provide a compelling assurance argument for the safety of decision making in AV in the presence of uncertainty.
Above research hypothesis can be further divided into the following research questions:
- Q1: Does considering the uncertainty in ML models in the decision-making process of an AV lead to improved safety (or more confidence in the safety)?
We further break down the research Question 1 into sub-questions as follows:- What are the various challenges in decision making process in an AV’s software pipeline?
- What is the source of uncertainty in the ML techniques that can affect the decision-making process in an AV?
- How uncertainties can be estimated and utilised for safe decision-making process?
- Q2: is it possible to create a compelling argument for safe decision making in AV that takes uncertainty in ML models into account?
We further break down the research Question 2 into sub-questions as follows:- What is the limitation in the existing safety standard and safety assurance cases related to ML in AV?
- What sort of evidence would we need to construct a safety case for probabilistic decision making?
In the next part of this blog, we will discuss various software architectures in detail. We will also discuss the challenges and limitation posed by uncertainty in the decision-making process.
Hierarchy in Human Driving
For AV to perform at par with human ability, we first need to understand human driving behaviour. For simplification, human driving tasks can be broken down into two categories of tasks, i.e., the ‘what tasks’ and the ‘how tasks’, together referred to as the orthogonal tasks. The driving task under the ‘what category’ can be further broken down into three hierarchical levels, i.e., navigation, guidance, and stabilisation. Similarly, the driving tasks under the ‘how category’ can be further broken down into three levels, i.e., skill-based, rule-based, and knowledge-based[4].
Table 1. Driving tasks and corresponding skill levels[5].
|
Driving Tasks |
Processing Levels |
|||
| Skill-based | Rule-based | Knowledge-based | ||
| Navigation | Daily Commute | Rule-based | Knowledge-based | |
| Guidance | Negotiating familiar junctions | Passing another car | Controlling a skid on icy roads | |
| Stabilization | Road following around corners | Driving an unfamiliar car | Learner on first lesson | |
The processing tasks for humans from left to right can be considered analogous to the ability of AV to generalise unseen or difficult tasks. Therefore, we can clearly observe that as we move more towards a higher level of autonomy in AV, as given in SAEJ3016, the dependency and complexity of the Machine Learning (ML) techniques also increase correspondingly.
System Architecture of hierarchical Software pipeline
The work by Ulbricht et al. on-System Architecture for AV proposes a Functional System Architecture based on the ISO26262 standard, i.e., a system architecture as a part of the system design which defines clear hierarchy and functional separation. The system architecture discussed below has real time implementation for an automated driving scenario in the Stand pilot project of Technical University of Braunschweig.
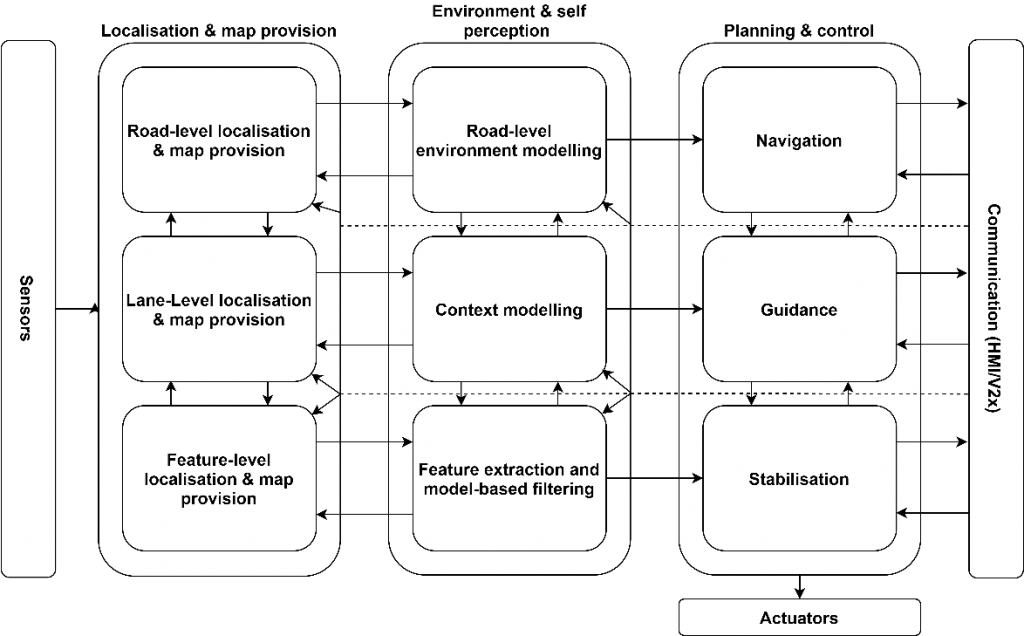
Figure 1. Functional System Architecture for AV software pipeline[6].
Based on the hierarchical driving tasks discussed in the previous section, the Functional System Architecture depicted above is divided vertically into three abstraction layers. The inputs to the Planning and Control block of the pipeline comes from the Localisation and the Perception blocks. The input and output from each of the sub-blocks represent the driving task hierarchy.
The functional system architecture can be broken down into five main groups as below:
- Sensors
- Localization and Map Provision
- Environment and Self-Perception
- Planning and Control
- Communication
Sensors
In AV, sensors are the primary source of information about the external and internal state of the ego vehicle. These sensors are categorised under three categories as mentioned below:
- Localisation Sensors: For example, GNSS
- Environment Sensors: For example, Camera, RADAR, LIDAR
- Vehicle Sensors: For example, IMU, Gyroscope, Brake Oil measurement
These sensors provide input to the Localisation & Map Provision and the Environment & Self-Perception blocks. These blocks in turn process the sensor data to generate the output required for the respective hierarchies of Planning and Control.
Localization and Map Provision
The primary tasks of this block are to maintain an up-to-date copy of a priori map by taking information from localisation sensors like GNSS and keeping it updated using the newly perceived image from the Environment & Self-Perception block. The upward facing arrows depict that the Localisation & Map Provision block subsumes information from the lower levels to detect, for example, the presence in a lane. Also, it helps to build the road topology from the detected and updated map features obtained from the Environment & Self-Perception block. Similarly, the downward facing arrows represent how information from higher levels, for example, the existence of a road in a priori map, can be used to establish a semantic relationship between the features detected at the lower levels.
Below are the tasks associated with Localisation & Map Provision:
- HD Maps: Due to relatively less computational power onboard an AV, and the limitation in sensor fusion technology, which is computationally very intense, an offline copy of a very detailed map needs to be maintained in the AV. This offline copy of a priori map is called an HD map. From now on, we will be repeatedly referring to HD maps which encapsulate the idea of the scene and the road topology provided as an input to the Planning and Control block[7].
- Feature level Localisation & Map Provision: The granular feature level information about Localisation and Perception, for example, detection of lane, dynamic element tracking, etc. is maintained and updated in an HD map.
- Lane Level Localisation and Map Provision: Dynamic information about moving objects are maintained and updated in an HD map in this block. For example, the classification of objects within lanes and drivable areas, using techniques like semantic segmentation performed in the Environment & Self-Perception block.
- Road-level Localisation & Map Provision: Top level information like road topology, lane structures, etc. are maintained and updated in an HD map.
Environment & self-perception
As depicted in the architecture above, the Environment & Self-perception block is at the heart of the software pipeline of the AV. It interacts with both the Localisation and Planning block, with the task to perceive and update the map for the Localisation block and the task to perceive and generate the scene/HD map for the Planning block.
- Feature extraction & model-based filtering: The bottom to up pipeline, of the Environment & Self-Perception block, uses the raw environment sensors and a priori feature level map to detect features like lanes, dynamic objects, traffic lights, etc. Within the same block, the output from the Feature extraction and model-based filtering sub-block is fed to the Context modelling sub-block above it. Apart from that, it feeds data to the stabilisation sub-block of the Planning & Control block and the feature-level sub-block of the Localisation & Map Provision block, both being adjacent to it. In the latter, this output is used to update the perceived environment feature to a priory map used earlier.
- Context Modelling: The output of the context modelling, i.e., a scene, is fed to the Guidance sub-block of the Planning & Control block. In addition, this output is also used to update the lane level prior map in the Localisation & Map Provision block.
- Road level environment modelling: All the information generated from the previous sub-blocks of the Environment & Self-Perception block is further used to generate and update a priori map from Localisation with the latest information. Last, all the information is used to create the road topology, traffic flow and lanes structure, etc. and the output generated from here is further used by the Navigation sub-block of the Planning and control block.
Planning and Control
The final step in a software pipeline is Planning and Control and this can be viewed as an integrator of the previous blocks. The different levels of hierarchy in driving tasks are clearly replicated here.
- Navigation: At the top, the navigation sub-block of Planning and Control is fed with the updated HD map from Environment & Self-Perception block. Navigation map uses information like road topology, traffic flow, lane hierarchy, to find various routes and waypoints. These routes are based on some optimisation criteria, for example fuel level. Also, this is where AV gets a human input via HMI.
- Guidance: To produce mission executable, the Guidance sub-block uses the route and scene information generated by the Environment & Self-Perception block. The scene is accessed and augmented with additional information to produce a specific situation for the ego vehicle based on the availability of an expert algorithm. The situation assessment is also dependent on the availability of skills to monitor the executable mission so produced. All this information is then processed by the behaviour planner to check the availability of various manoeuvres first and then select the best manoeuvre among them. The output of these manoeuvres is a range of possible different target poses required throughout the execution of the respective manoeuvre. These outputs are still at a tactical level i.e., they generate the possible manoeuvre and range of poses but do not generate a full velocity profile. Finally, it is from the Navigation sub-block that the execution monitoring communicates any changes due to the failure to execute a manoeuvre.
- Stabilisation: This block produces a trajectory for the respective manoeuvres. Trajectory is decided based on the available algorithms and the longitudinal and lateral control information is produced accordingly. The execution monitoring detects the deviation from the planned executables. Finally, this information is passed as the output to the actuators via a PID controller.
Communication (HMI/V2X)
The communication block interacts with all the blocks of the software pipeline. It communicates with other vehicles/communication infrastructure (like a remote operator, etc.) and with humans. Interaction with humans is usually at the top levels of the Planning & Control block, however, as the interaction also depends on the SAE level of automation, human interaction might be limited in the future. For example, at SAE level 5 of automation, human input may be only required to provide the driving mission goals, but at SAE level 3 of automation, the human input, in the form of taking over complete control, will be required in case of an adversary, i.e., an interaction at a lower level.
The V2X communication provides supplementary information which can further improve the overall accuracy of the AV. This, however, can be limited in application due to the data sharing laws of specific regions.
References
1. “Safety Report Waymo,” Energy Environ., pp. 101–103, 1990, doi: 10.1016/b978-0-08-037539-7.50012-0.
2. M. Bojarski et al., “End to End Learning for Self-Driving Cars,” arXiv1604.07316 [cs], pp. 1–9, Apr. 2016, Accessed: Sep. 02, 2019. [Online]. Available: http://arxiv.org/abs/1604.07316.
3. L. Gauerhof, P. Munk, and S. Burton, “Structuring Validation Targets of a Machine Learning Function Applied to Automated Driving,” in Computer Safety, Reliability, and Security, vol. 11088, Cham: Springer International Publishing, 2018, pp. 45–58.
4. Distinctions in Human Performance Models,” IEEE Trans. Syst. Man Cybern., vol. SMC-13, no. 3, pp. 257–266, 1983, doi: 10.1109/TSMC.1983.6313160.
5. R. Hale, J. Stoop, and J. Hommels, “Human error models as predictors of accident scenarios for designers in road transport systems,” Ergonomics, vol. 33, no. 10–11, pp. 1377–1387, 1990, doi: 10.1080/00140139008925339.
6. S. Ulbrich et al., “Towards a Functional System Architecture for Automated Vehicles,” arXiv1703.08557 [cs], pp. 1–16, Mar. 2017, Accessed: Sep. 02, 2019. [Online]. Available: http://arxiv.org/abs/1703.08557.
7. F. Gies, A. Danzer, and K. DIetmayer, “Environment Perception Framework Fusing Multi-Object Tracking, Dynamic Occupancy Grid Maps and Digital Maps,” IEEE Conf. Intell. Transp. Syst. Proceedings, ITSC, vol. 2018-Novem, pp. 3859–3865, 2018, doi: 10.1109/ITSC.2018.8569235.
About the Author: Vibhu Gautam
 Vibhu has studied System on Chip at the University of Southampton, where he graduated with a Master’s degree in 2010. The thesis for this Master’s was in the area of Machine Learning, titled as “A comprehensive approach of peak detection from mass spectrometer data using independent component analysis”. After finishing University, Vibhu worked as a Data Analyst, first for Mckinsey & Company and later for Boston Consulting Group (BCG). Before his current role as a researcher at the University of York, he was working as a Data Scientist at Micron Memory in Japan where he applied Advanced Machine Learning techniques for improving yield efficiency and predictive maintenance. His keen interest in Artificial Intelligence and Machine Learning (AI&ML) drove him back to academia and into this PhD.
Vibhu has studied System on Chip at the University of Southampton, where he graduated with a Master’s degree in 2010. The thesis for this Master’s was in the area of Machine Learning, titled as “A comprehensive approach of peak detection from mass spectrometer data using independent component analysis”. After finishing University, Vibhu worked as a Data Analyst, first for Mckinsey & Company and later for Boston Consulting Group (BCG). Before his current role as a researcher at the University of York, he was working as a Data Scientist at Micron Memory in Japan where he applied Advanced Machine Learning techniques for improving yield efficiency and predictive maintenance. His keen interest in Artificial Intelligence and Machine Learning (AI&ML) drove him back to academia and into this PhD.
![]()