
In this blog, I will be discussing how we can compute uncertainty for Deep Learning models which can provide us more confidence in deploying Deep Learning systems in safety-critical domains.
In recent years, deep learning (DL) models have seen considerable performance improvements particularly in computer vision and natural language processing (NLP) tasks. These models can achieve higher accuracy on a wide range of tasks such as image processing, text classification, text summarisation to name a few. Data and model uncertainties plague current state-of-the-art DL approaches [1]. Model uncertainty, also known as epistemic uncertainty, arises as a result of the model’s predicted reliance on training data. By giving adequate training data, this uncertainty can be reduced. Estimating model uncertainty is critical because of the difficulties in obtaining high-quality datasets in healthcare [2]. Furthermore, providing complete data is nearly challenging because DL models will almost always reflect an incomplete depiction of the real world [3]. In this blog, I will focus on measuring the uncertainty in the text classification task that is an fundamental component in conversational agents (CAs).
DL models are complex and use multiple hidden layers to process input. The outcome is produced using a softmax function in classification tasks. The softmax scores are a probability distribution over the class labels. The prediction is then chosen based on the label with the highest probability. The softmax function computes relative probabilities between classes but does not indicate how uncertain the DL model is in its prediction. One of the reasons this score can’t be utilised as a confidence metric for the model’s prediction is the stochastic nature of DL.
These models can be easily fooled by tempering with the input data such as adding noise in image data by changing pixels or providing out-of-distribution data for text or image classification models. To use these models in safety-critical systems, they must be able to provide a measure of certainty in their prediction. This will enable us to have more confidence in DL models.
CAs are automated assistants that utilise artificial intelligence (AI) and NLP to provide a natural response. Their utilisation in healthcare is growing as they can be used for a variety of tasks. For example, they can reduce the burden on clinical staff by providing 24-hour services, processing large amounts of data, providing empathy to patients, communicating in multiple languages over text and voice-based interfaces and many more. Typically, in healthcare, they utilise a task-oriented pipeline architecture which is shown in Figure 1. The components in this architecture are dependent on previous components input to produce an output.
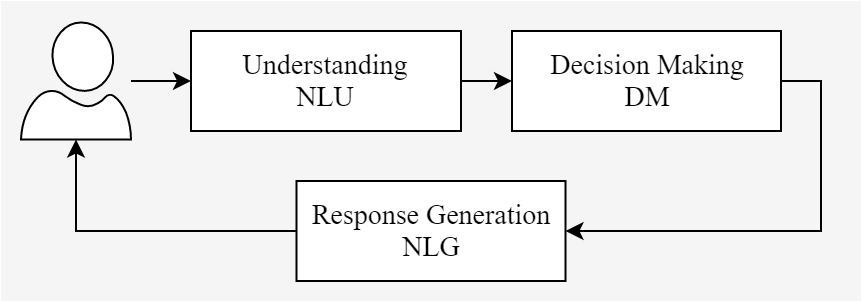
Figure 1: Task-oriented architecture of CAs
The NLU component in CA is responsible for intent classification and entity extraction tasks. For example, the sentence “I want to find nearby restaurants” can have an intent “find_restaurant”. The intent classes are chosen by the developers to group similar utterances to a class label which serves as the ground truth. Intent classification is a supervised text classification task in NLU. In this blog, I will focus on uncertainty measurement for this task. The reason is that decision making in CAs in task-oriented architecture is directly affected by incorrect intent classification. For intent classification tasks in CAs, DL models such as RNN and LSTMs are commonly utilised as they are better suited to time series data [4, 5]. In my work, I have used LSTM as a DL model for the intent classification task.
Bayesian techniques incorporate prior knowledge during inference, and this is useful in having more confidence in the model prediction. Machine learning (ML) or DL techniques learn from the data and the goal is to find a function that fits the data best. The parameter space (weights and biases) of DL models is very large which means there are various representations of a model that can best fit the data and we are going to utilise this approach to compute uncertainty. This approach is called Monte-Carlo (MC) dropout in which we drop out neurons at test time proposed by Gal et al. [6]. The MC dropout provides multiple models which are based on different parameters settings. The softmax values from each of the different parameter settings are averaged for new data. This allows us to have more confidence in our prediction as it also contains prior knowledge. The model uncertainty can then be computed using Shannon’s entropy method [7]. The entropy reflects the change or surprise element in the prediction based on our previous knowledge. If the value is too high, it means the current input is significantly different from the previous input and we can test our model by providing it with out-of-distribution inputs.
My proposed method to use this uncertainty management during intent classification in CAs is shown in Figure 2. I am going to discuss a use case in a clinical setting where this method would be useful. The use case represents a clinical setting where a CA is used for disease classification from users and based on the classification they are sent to the appropriate clinician. The CA is integrated with the hospital telephone line, and it reduces the need to manually listen to each call by the operator. This can save clinical staff’s time by deploying a CA. The patient will be sent to the wrong clinician if the intent classification is incorrect and if they need emergency care their health condition could be at risk. The entropy measure can help us to avoid this situation.
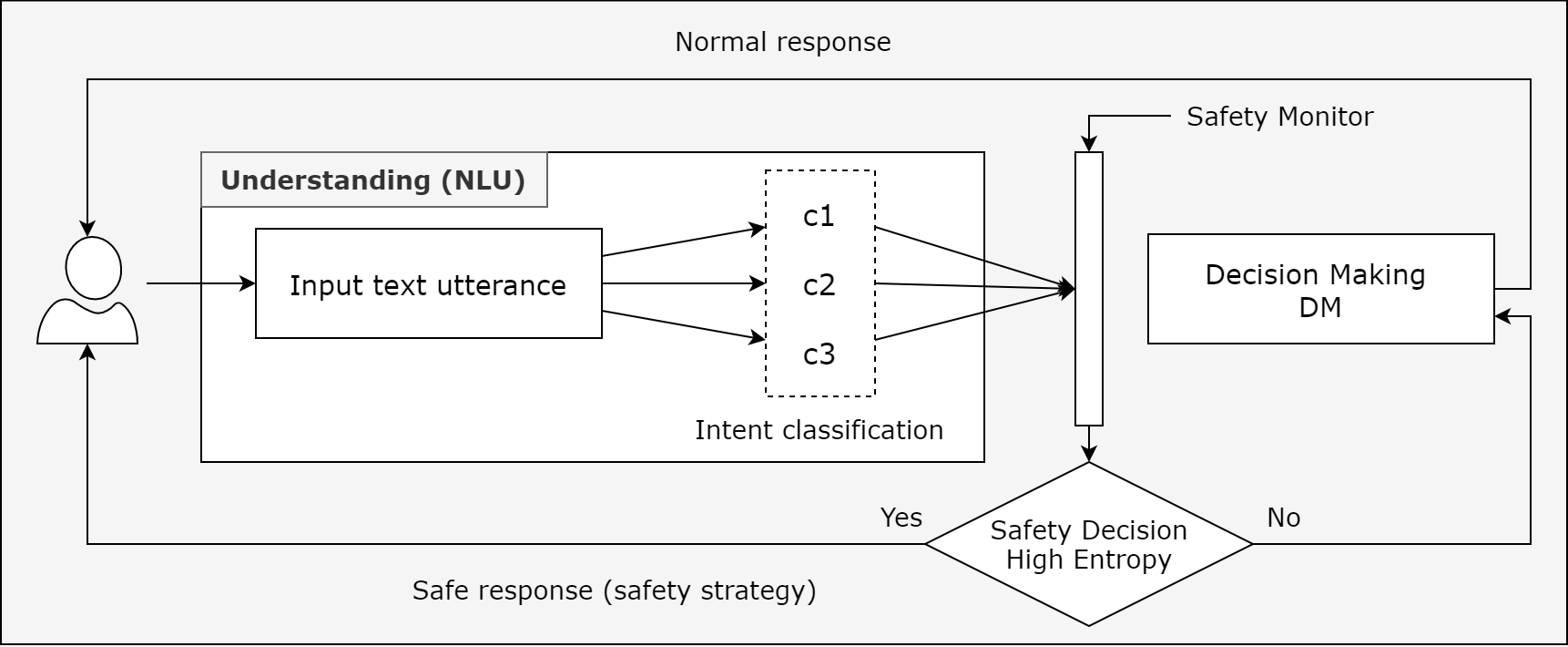
Figure 2: Safety architecture for clinical CAs
To implement this use case, I used a disease classification dataset from Kaggle containing 6661 examples [8]. I use an 80-20 ratio to train the model with 5661 examples and 1000 examples were retained for the test dataset. This dataset contains user utterances for a medical condition and the class label which identifies their symptom. Figure 3 presents a few data samples that we are going to use to train our LSTM.

Figure 3: Data samples for the use case
I build a Bayesian LSTM model on this dataset and the model accuracy on the test dataset was 99.4 per cent. The model was able to generalise well which can be seen from the performance on the test dataset. Apart from the accuracy model’s precision, recall, and F1-score were also in the reigns of 99 to 100 per cent and this means the model is not overfitting. The spread of class labels in the dataset was also even and the dataset examples were not skewed.
The uncertainty measurement on the test data from within the distribution refer to as in-distribution (ID) gave the results as shown in Figure 4. The entropy values were very low which suggest that data was from the same distribution that the model was trained on.

Figure 4: Uncertainty management on in-distribution (ID) data
I used an out-of-distribution (OOD) dataset for the evaluation of this method which is used to evaluate OOD methods in intent classification [9]. This dataset contains 1000 examples, and the results are shown in Figure 5. Notice the entropy values are much higher than the ID data.

Figure 5: Uncertainty management on out-of-distribution (OOD) data
The Bayesian method we applied can be used to devise a safe understanding of CAs based on my experiment. The evaluation dataset was of the same size as the test dataset which is a good number. Overall results were very promising, and I believe this approach can make the DL models robust and this method can also be applied in other domains. This work has also been accepted at EAI Mobihealth 2021 conference proceedings [10].
References
[1] Y. Gal, “Uncertainty in deep learning,” Univ. Cambridge, vol. 1, no. 3, p. 4, 2016.
[2] R. Challen, J. Denny, M. Pitt, L. Gompels, T. Edwards, and K. Tsaneva-Atanasova, “Artificial intelligence, bias and clinical safety,” BMJ Qual. Saf., vol. 28, no. 3, pp. 231–237, 2019, doi: 10.1136/bmjqs-2018-008370.
[3] L. Gauerhof, P. Munk, and S. Burton, “Structuring validation targets of a machine learning function applied to automated driving,” in International Conference on Computer Safety, Reliability, and Security, 2018, pp. 45–58.
[4] S. Louvan and B. Magnini, “Recent Neural Methods on Slot Filling and Intent Classification for Task-Oriented Dialogue Systems: A Survey,” arXiv Prepr. arXiv2011.00564, 2020.
[5] K. Yao, B. Peng, Y. Zhang, D. Yu, G. Zweig, and Y. Shi, “Spoken language understanding using long short-term memory neural networks,” in 2014 IEEE Spoken Language Technology Workshop (SLT), 2014, pp. 189–194.
[6] Y. Gal and Z. Ghahramani, “Dropout as a bayesian approximation: Representing model uncertainty in deep learning,” in international conference on machine learning, 2016, pp. 1050–1059.
[7] Y. Zheng, G. Chen, and M. Huang, “Out-of-domain detection for natural language understanding in dialog systems,” IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 28, pp. 1198–1209, 2020.
[8] P. Mooney, “Medical Speech, Transcription, and Intent,” 2019. https://www.kaggle.com/paultimothymooney/medical-speech-transcription-and-intent (accessed Apr. 20, 2021).
[9] S. Larson et al., “An evaluation dataset for intent classification and out-of-scope prediction,” arXiv Prepr. arXiv1909.02027, 2019.
[10] E. MobiHealth, “EAI MobiHealth 2021 Accepted Papers.” https://mobihealth.eai-conferences.org/2021/accepted-papers/ (accessed Dec. 21, 2021).
About the Author: Haris Aftab
 Haris has recently completed his master’s degree in Computer and Information Security from South Korea in February 2019. His area of research was ensuring interoperability in IoT standards. Before that, he worked in the IT industry for about 5 years as a Software Engineer for the development of mobile applications of Android and iOS. His interest in technology, mobile devices, IoT, and AI having a background in Software Engineering brought him to work in this exciting domain.
Haris has recently completed his master’s degree in Computer and Information Security from South Korea in February 2019. His area of research was ensuring interoperability in IoT standards. Before that, he worked in the IT industry for about 5 years as a Software Engineer for the development of mobile applications of Android and iOS. His interest in technology, mobile devices, IoT, and AI having a background in Software Engineering brought him to work in this exciting domain.
![]()