
In this blog, the several stages of a conventional LiDAR-based detection pipeline are discussed.
LiDAR-based detection is one of the popular sensor modalities in perception systems. Compared with the camera-based channel, the fusion of LiDAR information could utilize the heterogenous characteristics within the perception pipeline so that perceptual uncertainty could be mitigated [1]. For example, the passive sensors (cameras) are often very constrained by the degraded weather conditions, such as rainy, foggy or snow conditions. Under such conditions, the cameras will be disturbed and will produce poor-quality images which are difficult for ML techniques to accurately infer. Additional auxiliary active sensors like LiDAR or Radar could make compensation to augment perception performance. The sensor characteristics lead to a specific profile which is described in figure.1 for camera, lidar and radar [2].
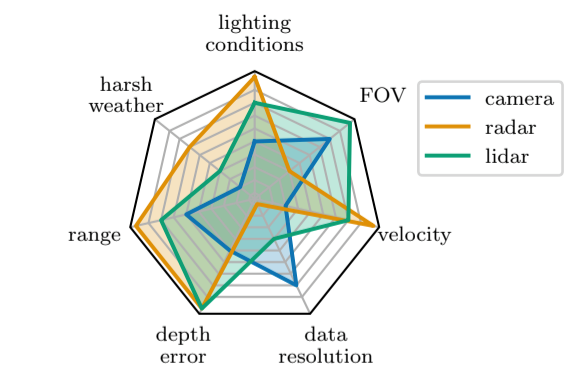
Figure 1. Quantitative comparison between the three major sensor modalities, from bad (center) to excellent (rim) [2].
To deal with failures from perception (e.g., Object Detector), researchers and practitioners have already considered using different types of conventional detection algorithms as a cross-check to compensate for some runtime ML failures. For instance, the Human Pose Evaluation (HPE) method [3] is used to evaluate whether the prediction of the human pose is correct or not. Such algorithms usually apply hand-crafted features for checking. In this blog, we would like to shift our attention to the traditional LiDAR-based detection pipelines, aiming to briefly explore the potential algorithms which could be applied for augmenting ML failures detection.
The conventional LiDAR-based detection pipeline is divided into 5 stages: preprocessing, ground segmentation, clustering the remaining points into instances, extracting hand-crafted features from each cluster, and classifying each cluster [4] (shown in figure 2).

Figure 2. Overview of a general conventional LiDAR-based detection pipeline.
For each stage, we summarize some typical study directions:
Preprocessing (registration)
The preprocessing phase mainly includes down-sampling, and Region-Of-Interest (ROI) settings. One of the common down-sampling methods is to voxelize the 3D point clouds into equally-sized cubic volume sets in order to decrease overall computation time of point clouds. ROI separation means that points clouds located at an unplanned 3D spatial environment will be filtered out. (see an example at Figure 3)
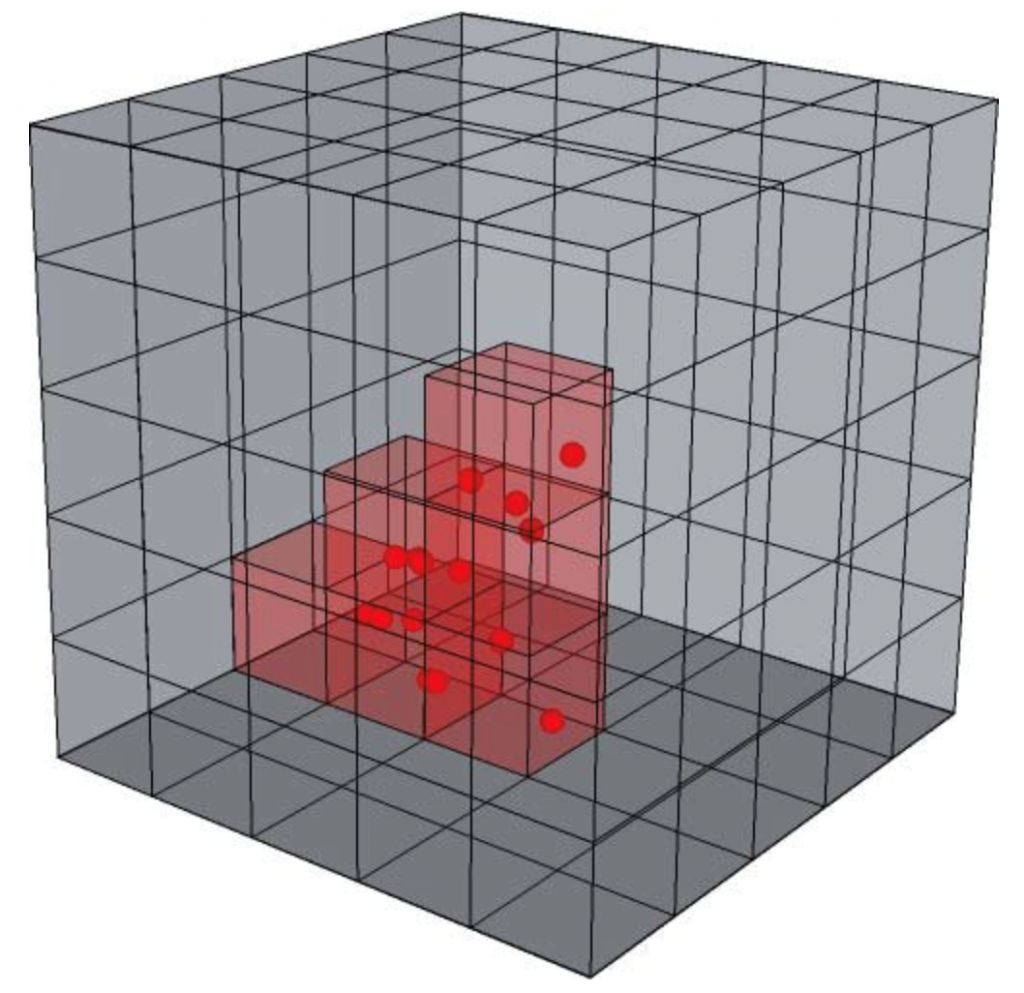
Figure 3. An example of voxelization [12].
Ground segmentation
The ground segmentation algorithm is used to remove ground plane points from the point clouds (see an example at Figure 4).

Figure 4. An example of ground segmentation (orange) and remaining points (red).
There are four basic types of filtering algorithms for ground segmentation, which are:
1) Ground segmentation algorithm based on spatial division.
It includes segmentation based on a 2D grid map [5], or 3D voxelization [6]. The 2D grid map is used to judge the ground plane by calculating the average elevation disparity in a certain field. The voxelization approach is based on a 2D grid map and partitions the 3D space into several sets based on the elevation of the point cloud. It distinguishes ground voxels from non-ground voxels by determining the mean or variance value of the heights of points within the voxels.
2) Ground segmentation algorithm based on scan lines.
For instance, [7] introduces an approach that the algorithm first identifies the local lowest point and then uses it as a seed to grow into a ground segment using slope and elevation information.
3) Ground segmentation algorithm based on local features.
The model-based filtering algorithms typically fit a local point set to a straight line or plane and match it to a generic model to identify ground points [8].
4) Ground segmentation algorithm based on additional information.
The information obtained from LiDAR data is limited, and it is difficult to achieve high ground filtering accuracy using these data. Currently, multi-sensor integration has become a trend, and researchers keep trying to filter ground points by fusing other devices to obtain additional information. Some algorithms use various additional information (like reflection intensity and the number of reflections) obtained from the LiDAR itself to separate ground and non-ground points [9].
Clustering
Once the ground points are removed, the remaining points are grouped according to spatial relationships between those points (Figure 5). One of the typical clustering algorithms is a Euclidean-based clustering algorithm. The points are clustered with respect to the Euclidean distance between them [6]. [10] uses a Radially Bounded Nearest Neighbor (RBNN) to cluster distinct objects in the point clouds.

Figure 5. An example of clustered points based on Euclidean distance, displayed in different colors. [Experimental data from a SAS consortium member]
Extraction and Classification
At these two stages, the design principle is used to extract object features and make the classification. [11] introduces an approach that use local points properties and global feature to capture object properties, like object’s dimensions or volume etc (Figure 6). Then, a Support Vector Machine (SVM) classifier is trained to classify objects.

Figure 6. Some hand-labeled properties of point clouds used for training a classifier [11].
To sum up, the studies of conventional LiDAR-based detection pipelines are intended to derive possible stages to represent obstacle information which could be used to compensate for failures from vision-based channels. Since it is impractical to develop multiple additional add-ons of the system, it is reasonable to derive existing resources from sensor modalities as ‘partial redundancies’ to make compensation. The less processing pipeline we can extract from the existing resources, the lower probability of common-cause of failures compared with the main channel using ML techniques. Therefore, based on standard dependability design patterns (i.e., N-Self-Checking Program), we will propose our solution regarding how to derive existing sensor resources with a minimum computation pipeline to augment the ability to detect ML failures.
References
1. Van Brummelen, Jessica, et al. “Autonomous vehicle perception: The technology of today and tomorrow.” Transportation research part C: emerging technologies 89 (2018): 384-406.
2. Reichert, Hannes, et al. “Towards Sensor Data Abstraction of Autonomous Vehicle Perception Systems.” arXiv preprint arXiv:2105.06896 (2021).
3. Jammalamadaka, Nataraj, et al. “Has my algorithm succeeded? an evaluator for human pose estimators.” European Conference on Computer Vision. Springer, Berlin, Heidelberg, 2012.
4. Wu, Bichen. Efficient deep neural networks. University of California, Berkeley, 2019.
5. Thrun, Sebastian, et al. “Stanley: The robot that won the DARPA Grand Challenge.” Journal of field Robotics 23.9 (2006): 661-692.
6. Kumar Rath, Prabin, Alejandro Ramirez‐Serrano, and Dilip Kumar Pratihar. “Real‐time moving object detection and removal from 3D pointcloud data for humanoid navigation in dense GPS‐denied environments.” Engineering Reports 2.12 (2020): e12275.
7. Montemerlo, Michael, et al. “Junior: The stanford entry in the urban challenge.” Journal of field Robotics 25.9 (2008): 569-597.
8. Moosmann, Frank, Oliver Pink, and Christoph Stiller. “Segmentation of 3D lidar data in non-flat urban environments using a local convexity criterion.” 2009 IEEE Intelligent Vehicles Symposium. IEEE, 2009.
9. Zhou, Weiqi. “An object-based approach for urban land cover classification: Integrating LiDAR height and intensity data.” IEEE Geoscience and Remote Sensing Letters 10.4 (2013): 928-931.
10. Luo, Zhongzhen, Saeid Habibi, and Martin V. Mohrenschildt. “LiDAR based real time multiple vehicle detection and tracking.” International Journal of Computer and Information Engineering 10.6 (2016): 1125-1132.
11. Himmelsbach, Michael, et al. “LIDAR-based 3D object perception.” Proceedings of 1st international workshop on cognition for technical systems. Vol. 1. 2008.
12. Schmitt, Michael. Reconstruction of urban surface models from multi-aspect and multi-baseline interferometric SAR. Diss. Technische Universität München, 2014.
About the Author: Yuan Liao
 Yuan Liao, majoring in embedded systems, obtained a dual master’s degree at ESIGELEC in France and USST in China in 2016. Then he started 3-year work as a software engineer in the field of automotive. He accumulated experiences in the field of software engineering and is interested in further researching in this field, which drove him for pursuing the PhD. Here he will carry out research in the area of autonomous systems to study the implementation of an adaptive platform for safer autonomous systems in the industry.
Yuan Liao, majoring in embedded systems, obtained a dual master’s degree at ESIGELEC in France and USST in China in 2016. Then he started 3-year work as a software engineer in the field of automotive. He accumulated experiences in the field of software engineering and is interested in further researching in this field, which drove him for pursuing the PhD. Here he will carry out research in the area of autonomous systems to study the implementation of an adaptive platform for safer autonomous systems in the industry.
![]()