
There are many development platforms to assist developers in building a chatbot quickly and efficiently. There is a trade-off of easiness versus control over these frameworks, where closed source is often easier to use while open-source often provides more control. This blog discusses the open-source RASA framework which provides more control over the development and fine-tuning of ML models.
Conversational agents (CAs) use artificial intelligence (AI) to provide a natural language response. They are common in various industries such as healthcare, e-commerce, sports, etc. The typical architecture of these CAs consists of a pipeline presented in Figure 1. Automatic speech recognition (ASR) and text to speech (TTS) are required for CAs which work on voice interfaces. The spoken/natural language understanding (SLU/NLU) understands the message and the dialogue manager (DM) then generates the next action. The knowledge base (KB) can be thought of as an external data source such as a database to retrieve some information. The natural language generation (NLG) generates the response based on the actions generated by the DM in a human-understandable form.

Figure 1: Architecture of Conversational Agents
There are many development platforms to assist developers in building a chatbot quickly and efficiently without having to develop them from scratch. Some of those popular frameworks include Google Dialog Flow, Amazon Lex, Microsoft LUIS, IBM Watson etc. The problem with some of the close source solutions is that although they are easier to implement you cannot tune or modify or even understand what is going under the hood of the machine learning (ML) model. There is a trade-off here of easiness versus control over these frameworks. Luckily enough, some open-source solutions such as RASA provide more control over the development and fine-tuning of ML models.
RASA belongs to the open-source category which provides a balance of having control of the development methods and at the same time provides wrapper classes in its library to help speed up the development process. It has strong community support so the bugs can be posted, and they are resolved in upcoming versions. In terminology, RASA can be thought of as a grey-box solution where there are controls available to choose different ML models, adjust hyper-parameters for the models and write custom components. This is unlike Google DialogFlow or Amazon Lex which are black-box solutions and whose customisation of models is limited. The architecture of the RASA open source is shown in Figure 2. The input/output channels can be either text or speech and currently, RASA does not officially provide a speech interface. The dialogue policies in RASA are reminiscent of the DM in conventional architecture and the action server is used for executing custom actions with the help of the KB.
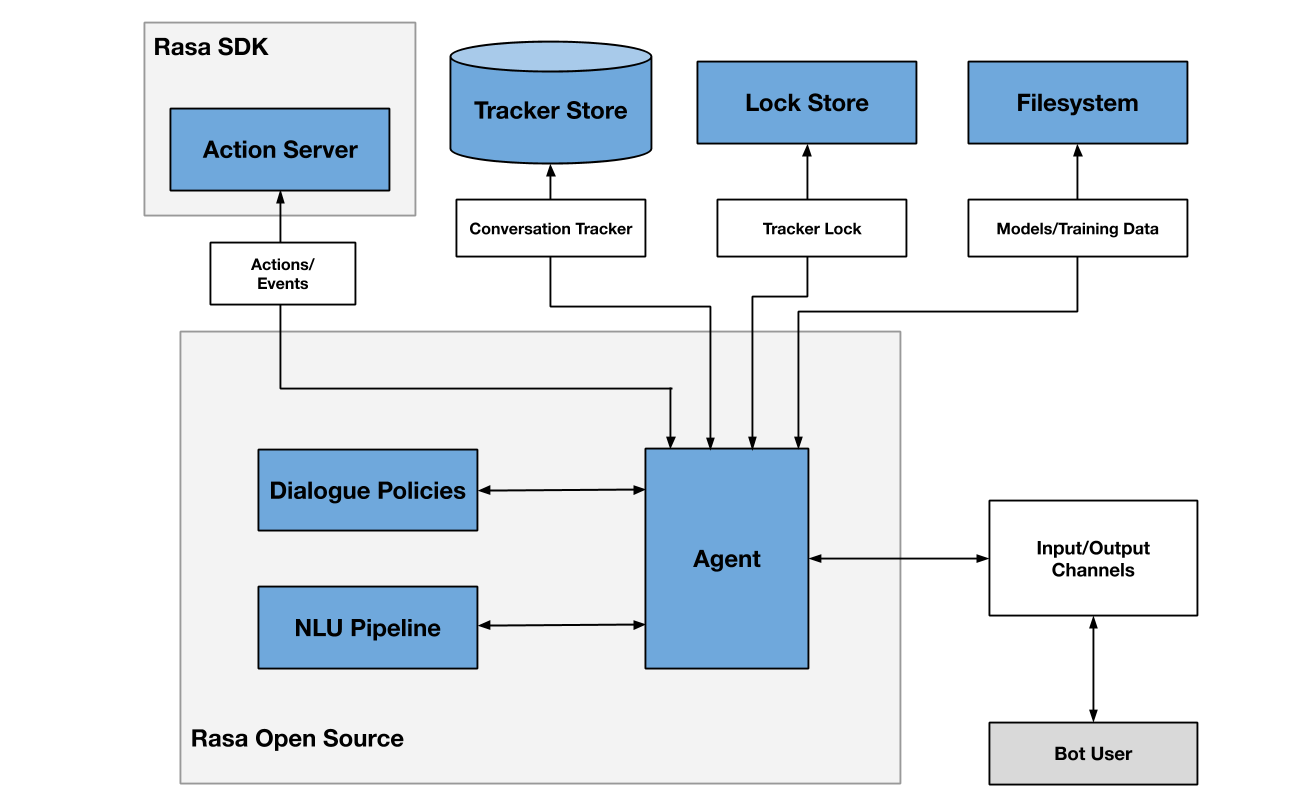
Figure 2: RASA Architecture [1]
Currently, RASA does not provide a voice API for ASR and TTS support, but custom Google’s or Amazon’s ASR and TTS components can be integrated easily. Further, RASA provides support to integrate with third-party interfaces such as Slack, Telegram, Facebook Messenger and many more. There is also support in RASA to write your custom connector class in Python to use CA on any interface of choice, for example, embedding it into your website.
RASA provides a flexible approach to building a CA in that the NLU pipeline can be customised based on the problem that the CA is going to solve. The NLU pipeline typically consists of a language model, a tokenizer to split the sequence into words followed by a featurizer component to convert those text tokens into a numeric format. An example NLU pipeline in RASA is shown in Figure 3. The order of components in the NLU pipeline can easily be customised to add or remove components.
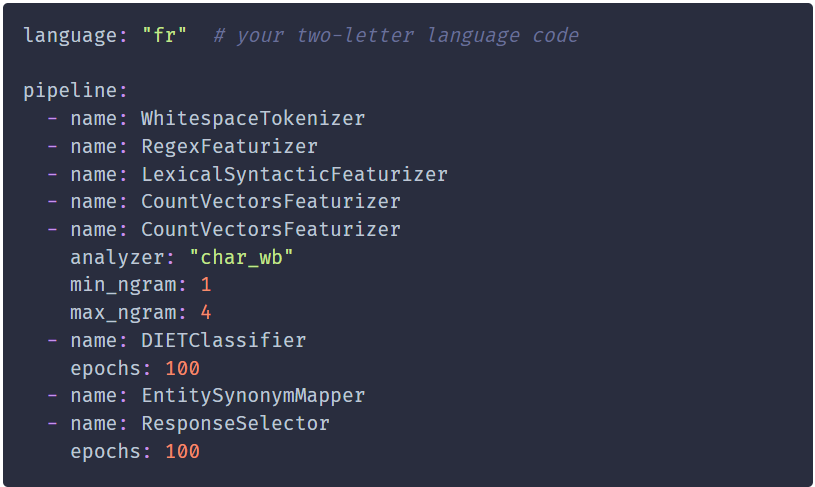
Figure 3: Example NLU pipeline [2]
The training of NLU models is also easy and a training data file is added with initial intents when a new project is created in RASA. Adding training examples is straightforward for NLU models. Figure 4 shows a RASA code snippet for NLU training data for multiple intents. There are state of the art deep learning (DL) models such as Transformers as well as support for classic models such as SVM for the NLU classifier.
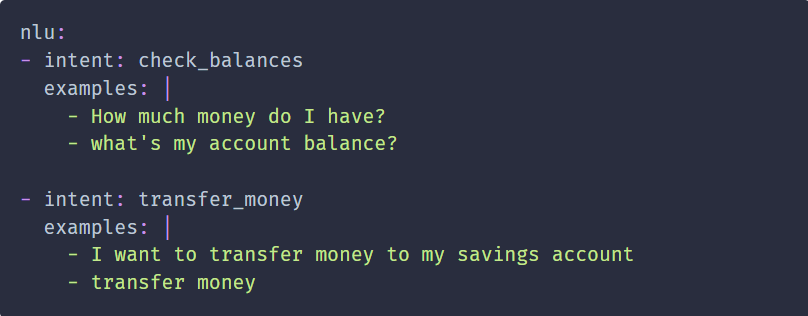
Figure 4: RASA NLU training examples [2]
For DM, RASA also provides various dialogue policies which decide what action the CA is going to take next based on current user input. There are rule-based policies, so the CA must follow a defined set of steps for a task as well as ML policies. There is also the support of ensemble policies and RASA decides the next action based on the priority of a policy if more than one is used to determine the next action. Training data for ML policies are called stories in RASA. Each story provides a path a user may take during the execution. Figure 5 displays an example of how training data can be provided for the DM. The ‘steps’ keyword defines the order in which we think the user is going to proceed to complete the booking at a restaurant. The ‘intent’ defines what the user is going to say and ‘entities’ are keywords to help execute the action. The response provided by the CA is based on the ‘action’ keyword.
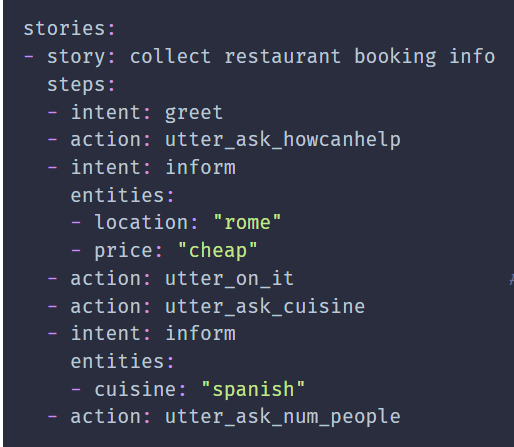
Figure 5: Writing training data for DM in RASA [3]
For custom actions, RASA provides a flexible approach whereby the NLU values can be accessed in the custom action class for validation purpose. The actions are executed in a separate server which provides a separation of concern between the NLU and the DM code. which is a flexible approach to building large scale CAs. NLG actions are based on fixed response templates, and RASA do provide the flexibility of generating an end-to-end response based on ML, but this feature is still in beta and not mature.
Once CA development is complete, RASA also provides an online deployment platform, RASA X, that can be shared with real users and testers to get real-life data. It is difficult for an ML model to make good predictions without real and quality data. RASA X is a great tool for overcoming the lack of data in building a CA. Further, the tool also provides statistics of errors and based on that the overall performance of CA can be enhanced. The process of RASA X can be seen in Figure 6.
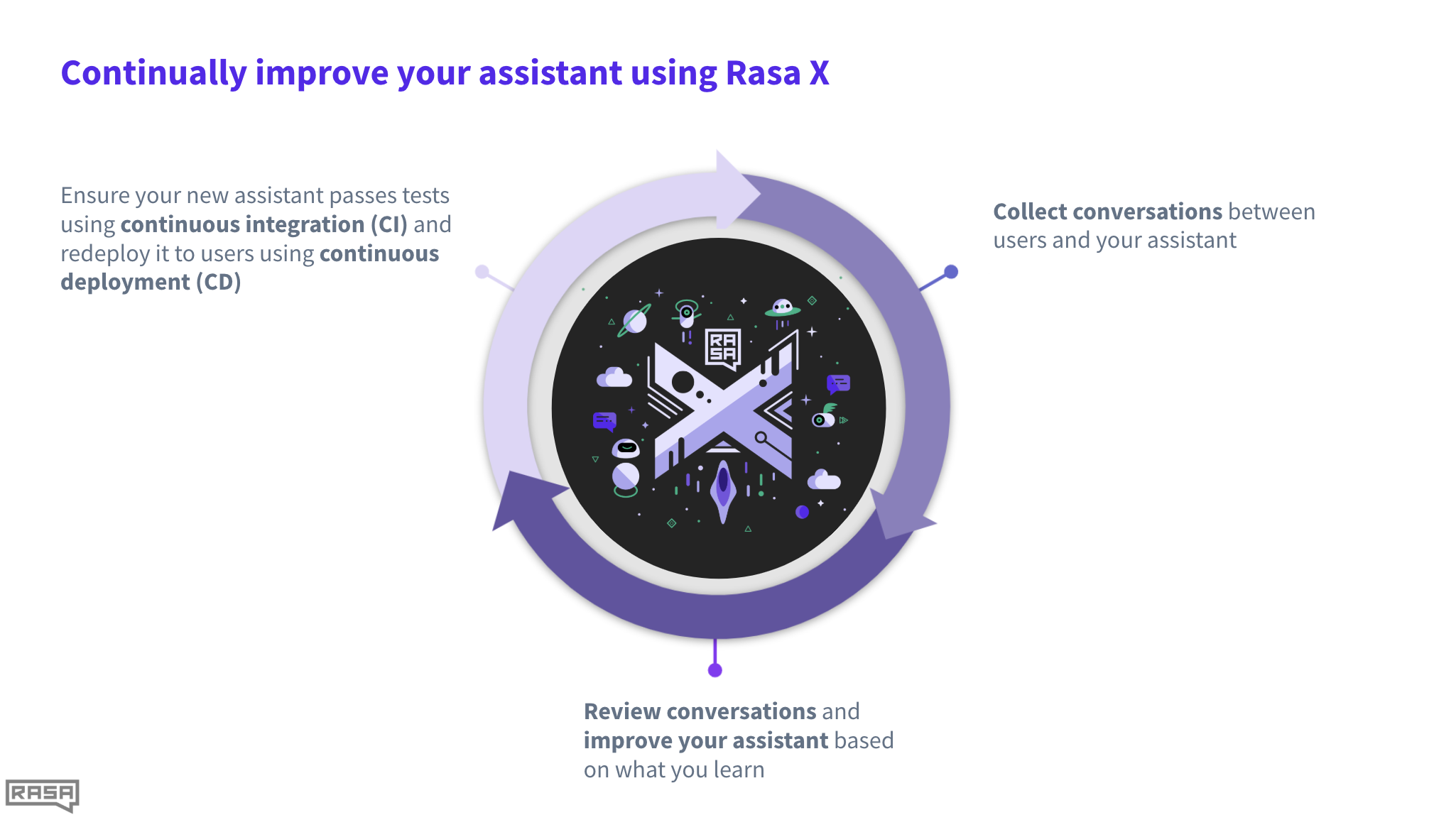
Figure 6: RASA X process
For my research work, to identify the safety failure concerns, I developed a CA using RASA because it provides an end-to-end CA development that is flexible and customizable with the latest ML and DL models and takes less amount of time. In summary, flexibility of using different language models, selecting state-of-the-art model for NLU and DP, integration with popular messaging channels, and deployment server options to test and gather real-world data continuous integration (CI) are core strengths of RASA over other platforms. The community for developers is a good place to share issues and get solutions and feedback. There is also great support available in the form of tutorials on the official channel of RASA on YouTube.
References
[1] RASA, “Rasa Architecture Overview.” https://rasa.com/docs/rasa/arch-overview/ (accessed Dec. 20, 2021).[2] RASA, “Tuning Your NLU Model.” https://rasa.com/docs/rasa/tuning-your-model/ (accessed Dec. 20, 2021).
[3] RASA, “Stories.” https://rasa.com/docs/rasa/stories (accessed Dec. 20, 2021).
[4] RASA, “Introduction to Rasa X.” https://rasa.com/docs/rasa-x/ (accessed Dec. 20, 2021).
About the Author: Haris Aftab
 Haris has recently completed his master’s degree in Computer and Information Security from South Korea in February 2019. His area of research was ensuring interoperability in IoT standards. Before that, he worked in the IT industry for about 5 years as a Software Engineer for the development of mobile applications of Android and iOS. His interest in technology, mobile devices, IoT, and AI having a background in Software Engineering brought him to work in this exciting domain.
Haris has recently completed his master’s degree in Computer and Information Security from South Korea in February 2019. His area of research was ensuring interoperability in IoT standards. Before that, he worked in the IT industry for about 5 years as a Software Engineer for the development of mobile applications of Android and iOS. His interest in technology, mobile devices, IoT, and AI having a background in Software Engineering brought him to work in this exciting domain.
![]()